BCQuality
At Directions NA, Microsoft laid out its vision for the future of Business Central development. As you might expect, it’s an agentic one. The role of an AL developer is moving toward an agentic workflow — how far and how fast will depend on many factors, but the direction is clear. One of the first concrete steps in that direction is a repository called BCQuality, and the description on the repo sums it up well: «Quality skills and knowledge for Business Central development. The shared bar for humans and agents alike.»
At first glance it looks like another best-practices repository. 99 knowledge files in the Microsoft layer, 14 more in the community layer, 4 global skills (1 entry-point and 3 meta-skill contracts), 7 review skills. Nothing could be further from the truth — there’s much more to it, and it’s interesting in ways that aren’t obvious from the inventory.
As you read through it, what stands out is not the inventory itself but the logic the maintainers use to decide what gets in and what stays out. That logic is worth understanding because it shapes everything else.
Disclaimer: the repo says it openly — «Large and potentially breaking changes are expected. Public preview will soon be announced.»
The remedial filter: why BCQuality applies it
BCQuality presents itself as a remedial knowledge base. Let’s pin down what that means.
A remedial knowledge base is a repository of information whose purpose is to remedy — to fix gaps, errors or blind spots in people, teams or processes. It can serve training, technical support, quality assurance or continuous improvement. In general terms, a knowledge base is a structured set of information (rules, guides, solutions, best practices) that can be searched, retrieved and applied systematically. The remedial qualifier adds a specific intent: the content exists to repair, reinforce or close gaps. For example:
- reinforcing concepts that were poorly learned,
- correcting recurring errors in a process,
- remediating common quality issues in how a product is used.
The qualifier matters. The admission rule the maintainers apply isn’t about quantity or relevance — it boils down to one question about how an LLM behaves when you don’t remind it of something:
If this file did not exist, would a modern LLM reviewing or generating BC code make a mistake this file would have prevented?
If the answer is no — because the guidance is generic, or because the model already has the mechanic down — the file doesn’t make it into the repo, no matter how correct or relevant the content is. The rule sounds harsh written like that, but it’s easier to grasp with a couple of examples.
Imagine these two sentences. The first one you’ll find inside BCQuality. The second one you won’t.
«SetLoadFields must be called before filters, not after.»
«Don’t hardcode secrets.»
Both are true and both are good practices. The difference is in how an LLM behaves when you don’t remind it. The second one — «don’t hardcode secrets» — any decent model applies on its own: ask it for a service that calls an API and it gives you back code that reads the credential from a secret store, not a literal in the .al. The first one, by contrast, slips through easily. If you ask the model to reorder code and put SetLoadFields after SetRange because «it reads cleaner that way,» it does so without flinching — and the query plan stops folding the fields the way you expected. Order matters here, but it’s one of those BC runtime details the model doesn’t have nailed down.
That’s the idea behind the remedial filter: include only the knowledge an LLM doesn’t already apply on its own. The README offers more examples in the same vein — contrasting cases that an agent can identify and apply easily.
Good fit: FindSet(true) (which activates record locking for editing, and the second parameter of its signature is now obsolete) or CodeCop AA0233 (the rule that flags FindFirst...Next loops, a pattern the model doesn’t connect to the rule number). Poor fit: «use HTTPS instead of HTTP» or «keep transactions short». These are important truths, but the maintainers don’t add them because any modern LLM already applies them on its own.
This rule changes how you measure the success of a repository like this. The question stops being «how many rules do we have?» and becomes «how many times did the agent get something wrong because a file was missing?». When an agent reviews a PR and lets something through that should have been caught, the answer isn’t to tweak the prompt — it’s to write the knowledge file that wasn’t there.
To see this clearly, it helps to contrast two models:
- Traditional best-practices repository. A typical success metric would be «we have 500 rules covered.» More rules = better repo.
- The model BCQuality proposes. That metric doesn’t apply. If you add 500 rules the LLM already knows, the repo doesn’t improve — it gets worse, because it dilutes what’s actually useful. The success metric becomes «how many errors does the agent make that one of our files would have prevented?».
When I say «file» I mean the atomic unit of BCQuality: a knowledge file. It’s a single .md with YAML frontmatter that covers exactly one idea — for example, microsoft/knowledge/performance/filter-before-find.md doesn’t talk about «performance in general» but specifically about «you must call SetRange/SetFilter before FindSet, and here’s why». Under 100 lines, no code inside (examples live in sibling files .good.al / .bad.al), one mandatory ## Description section and two recommended ones: ## Best Practice and ## Anti Pattern. The last one is what a review agent reads to detect the pattern in new code.
The «file» is the unit of measure because it’s the unit of citation: when a review skill flags a finding, the JSON points at the exact path of the knowledge file that justifies it. That way, counting «errors a file would have prevented» is not a metaphor — you can measure it literally: for every false negative the agent produces in a PR, someone has to be able to point to the missing file (or decide to create it).
This is why the improvement loop for the repo is very concrete: if the number of uncaught errors is high, there are gaps to fill — time to write new knowledge files. If it’s low, BCQuality is doing its job. The WRITE rule (skills/write.md) defines exactly how to author one of those files so it passes CI: one idea per file, complete frontmatter, correct sections, no fenced code blocks.
Vocabulary worth knowing: five words before moving on
Before getting into how the repo is organised, it helps to pin down the vocabulary, because BCQuality reuses common terms with very specific meanings:
- Knowledge file: an atomic markdown file with YAML frontmatter. One idea per file, under 100 lines, no code blocks inside. Code examples live in sibling files
<slug>.good.al/<slug>.bad.al. - Action skill: a markdown file an agent executes (
kind: action-skill). It applies the four-step pattern over the knowledge files and emits a JSON document with findings. - Meta-skill: a contract about how things work (
kind: meta-skill). BCQuality has three (READ, DO and WRITE) that live in/skills/together with a fourth file, Entry, which is a different kind (kind: entry-point). - Orchestrator: the external tool that triggers the work. It lives outside BCQuality — it can be AL-Go, a VS Code extension, a GitHub Action or a development framework like ALDC. It knows when to run something, not what.
- Dispatch record: the JSON Entry returns when an orchestrator asks it what to do. It lists the action skills that apply, the ones being skipped and why.
With this in hand, the rest reads more easily.
- For partners:
/custom/offers a clean place to put internal knowledge (a customer’s rules, in-house patterns) without polluting the upstream layer. You fork, populate/custom/, point the orchestrator at the fork. - For the community:
community/skills/is empty and open. Any action skill proven in the field (a telemetry linter, an AL-Go pipelines reviewer, an AppSource auditor) has a place to live. - For existing community frameworks: all of us working in this space now have a common reference to align around. The hard meta-design problems (how to organise knowledge for an agent to consume, how to shape the output, how to handle precedence between layers) are already solved and locked.
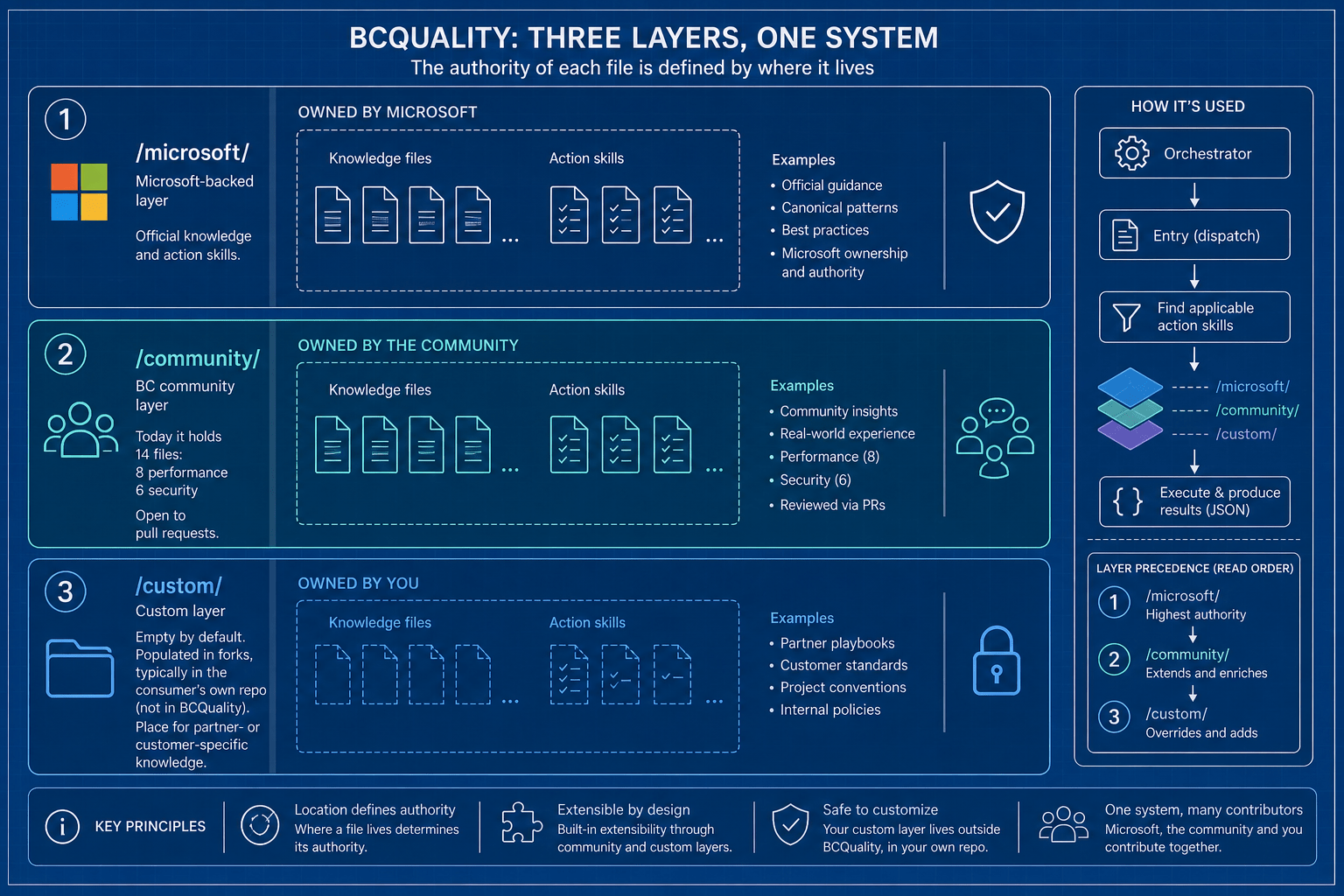
Organisation of BCQuality: a layered model
BCQuality is organised in three layers. The authority of each file is defined by where it lives:
/microsoft/— the Microsoft-backed layer. Official knowledge and action skills./community/— the BC community layer. Today it holds 14 files (8 performance, 6 security) and is open to pull requests./custom/— empty by default. It gets populated in forks, typically in the consumer’s own repo (not in BCQuality). It’s the place for partner- or customer-specific knowledge.
All three layers coexist when an agent consumes the repo. If two files conflict, the higher-precedence one wins (custom over microsoft over community for knowledge files; same ordering for skills, per READ and Entry). The discarded one is reported in the suppressed field (knowledge) or skipped / skipped-sub-skills (skills), so nothing is lost without leaving a trace.
Note (you can check this in the repo). Precedence between
microsoftandcommunityfor knowledge files is defined by READ as/custom/>/microsoft/>/community/. For skills, Entry applies/custom/>/community/>/microsoft/when two skills share the sameidacross layers. The difference is deliberate: official review skills can be replaced by a community or custom version with the sameid.
Above the layers, four global skills live in /skills/. The first one is Entry (entry.md), a router that receives the orchestrator’s goal and returns the dispatch record listing the action skills that apply. Structurally it follows the same four-step pattern as the action skills, but its output is the dispatch record itself, not findings.
The other three are the meta-skill contracts:
- READ (
read.md) — how to read a knowledge file: parsing the frontmatter, interpreting the sections, applying layer precedence. - DO (
do.md) — the template every action skill follows. It defines the Source → Relevance → Worklist → Action pattern and the JSON output contract. - WRITE (
write.md) — how to author a new knowledge file: atomicity rules, required sections, no fenced code blocks.
READ and DO are loaded on demand, typically when the agent runs the first action skill Entry has dispatched, so there’s no need to read them before invoking Entry. WRITE only comes into play when someone is authoring new content.
How an action skill works
An action skill follows the DO template and lives inside one of the layers. It comes in two flavours: leaf (evaluates knowledge files directly) and super-skill (composes other action skills via sub-skills). The canonical reference is al-code-review, a super-skill that composes six leaves: performance, security, privacy, upgrade, style and ui.
Every action skill — the official Microsoft one, a community one, or a /custom/ one you write tomorrow — returns the same JSON. That uniformity is what allows the orchestrator to consume any skill without skill-specific parsing. The schema lives in do.md and has five fields worth knowing:
outcome— the state of the run, in five values designed to remove ambiguity:completed: the skill ran end to end.findingsmay be empty (= all clear) or contain entries.not-applicable: the frontmatter filters didn’t match the context. The skill didn’t even look at the code.no-knowledge: the skill ran but found no applicable knowledge file. Different from «I found nothing to flag».partial: the skill started but didn’t finish (timeout, mid-run error). What was evaluated is reported; the rest isn’t.failed: the skill broke. The consumer should ignorefindingswhen the outcome isfailed.
ok/error) matters: a PR review that comes backnot-applicableis not the same as one that comes backcompletedwith zero findings, and treating them as if they were the same would lead to false greens in CI.findings— the list of things observed. Each finding carries:severityin four levels:blocker(breaks platform guarantees, can’t be merged),major(serious defect, fix before merging),minor(quality issue, doesn’t block),info(observation, not actionable). These four are what the orchestrator maps to build gates: typicallyblockercuts the build,majorleaves a hard comment,minorleaves a soft comment,infogets logged.message(human text),location(path + line, optional) andconfidence(high/medium/low: the skill states how sure it is that the finding is real — not how serious it is).
references— the part that prevents hallucinations. Every finding points to the repo-relative path of the knowledge file that justifies it (for examplemicrosoft/knowledge/performance/filter-before-find.md). If the skill can’t cite a file, it shouldn’t emit the finding. This is what separates an agent backed by BCQuality from one reviewing «by eye»: every complaint has a signed paper behind it.suppressed— the audit trail of layer precedence. If a/community/knowledge file gets overridden by a/microsoft/one with conflicting guidance, the overridden one isn’t deleted — it’s reported here with a reason (layer-precedenceorconfiguration). Nothing is lost silently.
When the skill returning the JSON is a super-skill (such as al-code-review, which orchestrates six leaves), two extra fields appear:
sub-results— the full report of each sub-skill, verbatim. The super-skill doesn’t summarise; it pastes the entire JSON of each leaf underneath. This lets the orchestrator render results at two levels: the aggregated rollup and the per-domain detail (performance, security, etc.).skipped-sub-skills— the leaves the super-skill chose not to invoke and why (configurationif the orchestrator turned them off,not-applicableif the available inputs didn’t satisfy what the leaf declares it accepts). Same idea assuppressed, but at the skill level instead of the knowledge-file level.
As an example, here’s a real fragment from the repo: al-code-review against a PR detects three things and returns
{ "outcome": "completed", "summary": { "counts": { "blocker": 1, "major": 1, "minor": 1, "info": 0 } }, "findings": [ { "severity": "blocker", "message": "Bearer token declared as Text and passed in clear in the HTTP request path.", "references": [{ "path": "microsoft/knowledge/security/use-secrettext-for-credentials.md" }], "confidence": "high" }, { "severity": "major", "message": "FindSet without a prior SetRange: full-table scan.", "references": [{ "path": "microsoft/knowledge/performance/filter-before-find.md" }], "confidence": "high" }, { "severity": "minor", "message": "SetLoadFields called after SetRange; the reversed order isn't folded into the plan.", "references": [{ "path": "community/knowledge/performance/call-setloadfields-before-filters.md" }], "confidence": "high" } ]}
Every finding points at the exact file that justifies it, so the human developer can open it and read the rule, and the agent can cite it without making things up.
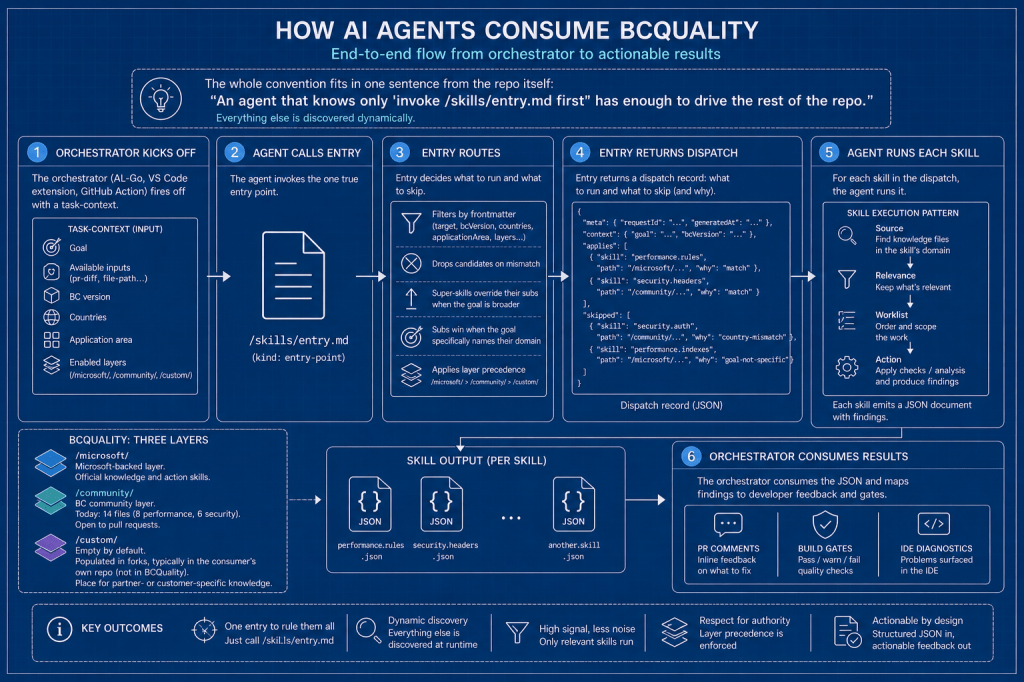
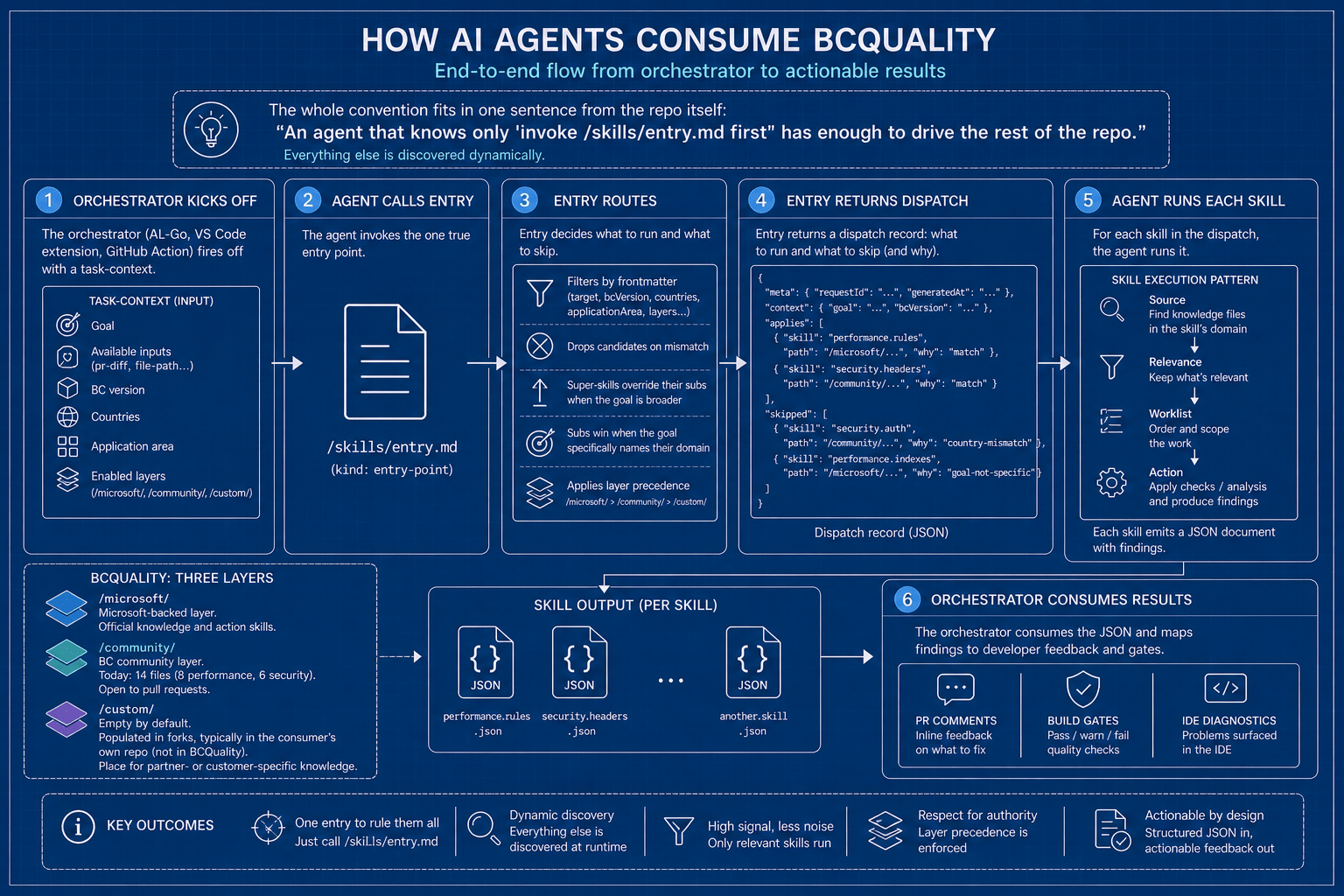
How AI agents consume it
The end-to-end flow is rather elegant because the whole convention fits in one sentence from the repo itself: «An agent that knows only ‘invoke /skills/entry.md first’ has enough to drive the rest of the repo.» Everything else is discovered dynamically.
- The orchestrator (AL-Go, a VS Code extension, a GitHub Action) fires off with a
task-context: goal, available inputs (pr-diff,file-path…), BC version, countries, application area, enabled layers. - The agent calls Entry. Entry routes: filters by frontmatter, drops candidates on mismatch, super-skills override their subs when the goal is broader (and subs win when the goal specifically names their domain), applies layer precedence — and returns the list that applies.
- For each skill in the dispatch, the agent runs it. The skill applies the Source → Relevance → Worklist → Action pattern over the knowledge files in its domain and emits a JSON document.
- The orchestrator consumes that JSON and maps the findings to PR comments, build gates or IDE diagnostics.
State of the art today
State as of May 2026:
- Microsoft layer — 99 knowledge files distributed as: performance 42, security 14, privacy 11, style 11, upgrade 11, ui 9, testing 1. Performance is well covered; the rest of the domains sit between 9 and 14 files, except testing, which is just getting started with one.
- Microsoft skills — 7 review skills: the super-skill
al-code-reviewand its six leaves (al-performance-review,al-security-review,al-privacy-review,al-upgrade-review,al-style-review,al-ui-review). - Community layer — 14 knowledge files (8 performance, 6 security). The remaining domains haven’t been seeded and
community/skills/is empty. - Custom layer — empty. Only the structure exists.
A reminder, again from the repo itself: «Large and potentially breaking changes are expected. Public preview will soon be announced.» So keep in mind that what’s here today may move.
Inspiring Conclusions
BCQuality isn’t a BC best-practices course — it’s the first time Microsoft has structured BC knowledge explicitly so that an agent can consume it. The admission rule does the heavy work: if your LLM already knows it, it doesn’t need to be in the repo, which keeps the content useful and focused.
The natural next step — for those of us who’ve been building skills and frameworks around GitHub Copilot and Claude Code in AL — is to ask which parts of our own work fit well in /community/ and which make more sense kept in their own repos. That conversation is for a second article.
The doors it opens are the most interesting part:
It will be interesting to watch how the «admission rule» evolves as the repo grows. The temptation to add «important guidance» even when any LLM already knows it is always there, and the remedial filter loses its meaning the moment we relax. If Microsoft holds the line, BCQuality can become a very useful piece of the ecosystem.
References
- Repository: github.com/microsoft/BCQuality
- AL Development Collection (a possible orchestrator)
- AL-Go for GitHub: github.com/microsoft/AL-Go (default orchestrator)










































Deja un comentario